Andrej Karpathy - Software Is Changing (Again)
Published on Friday, 20-06-2025
(Summarized from https://www.youtube.com/watch?v=LCEmiRjPEtQ)
Software is Changing (Again): Key Insights from Andrej Karpathy
Andrej Karpathy, former Director of AI at Tesla, argues that we are in a truly unique and interesting time for software development, as “software is changing, again”. He suggests that software hasn’t seen such fundamental shifts in 70 years, and we’ve experienced two rapid transformations in just the last few years. This means a massive amount of software needs to be written and rewritten.
Karpathy outlines three distinct “Software” paradigms:
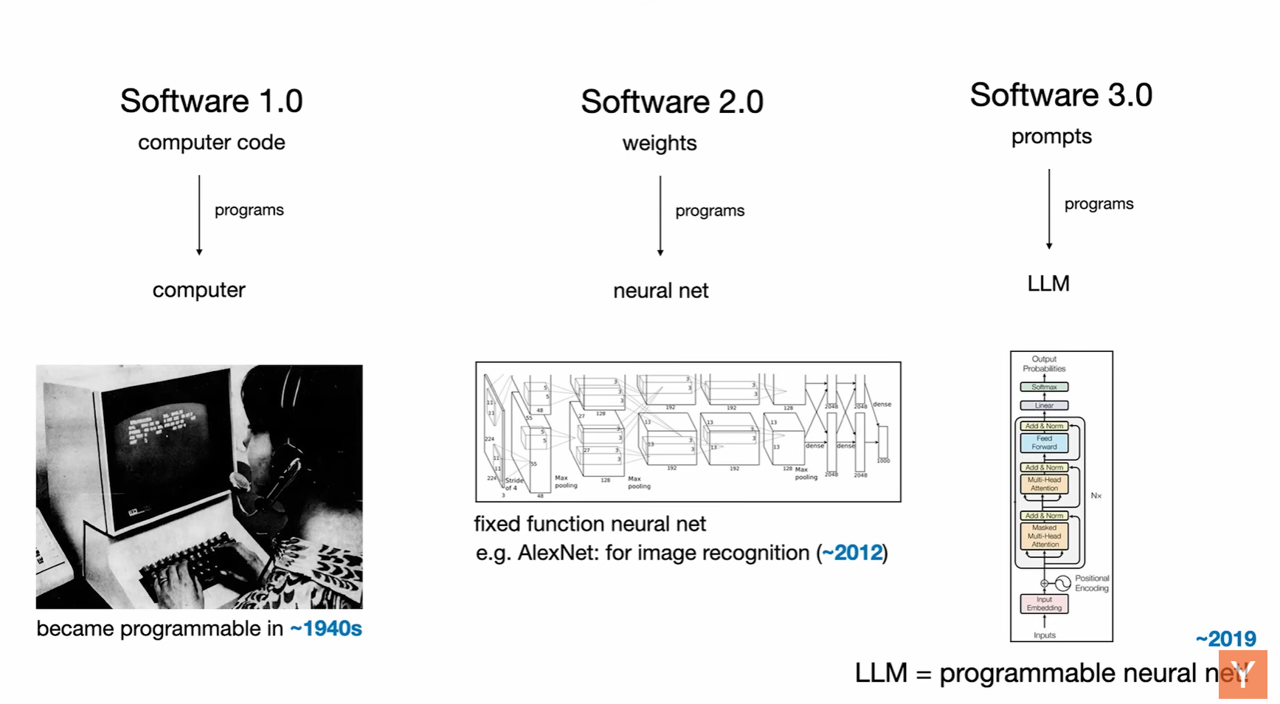
Software 1.0: The Code You Write
This is the traditional programming paradigm where humans write explicit code, like C++ or Python, to give instructions to a computer. This kind of software involves direct instructions for carrying out tasks in the digital space.
Software 2.0: Neural Networks and Data-Driven Programming
Software 2.0 refers to neural networks, specifically their weights. Instead of writing code directly, developers tune datasets and use optimizers to create the parameters of the neural network. Karpathy likens Hugging Face to the “GitHub of Software 2.0,” where models are shared and visualized. An example is AlexNet, an image recognizer neural network. At Tesla, Karpathy observed Software 2.0 (neural networks) “eating through” the Software 1.0 (C++ code) stack in the autopilot system, as capabilities migrated from explicit code to learned neural networks.
Software 3.0: Programmable Large Language Models (LLMs)
This is the newest paradigm, where neural networks, specifically Large Language Models (LLMs), become programmable. Karpathy designates this as Software 3.0, and the remarkable aspect is that prompts, often written in English, are now the “programs” that program the LLM. This represents a new kind of computer and a very interesting programming language. He notes that much of the code seen on GitHub now intersperses English with traditional code, highlighting this new category.
LLMs as Operating Systems: A Powerful Analogy
Karpathy draws several compelling analogies to help us understand LLMs:
Utilities: LLMs, like electricity, are costly to build (capex) and serve (opex) through metered access. Their widespread reliance means that when state-of-the-art LLMs go down, it’s akin to an “intelligence brownout in the world”.

Fabs: The significant capital expenditure required to build LLMs, along with the rapid growth of the underlying technology tree and centralized research within LLM labs, makes them comparable to fabrication plants (fabs).

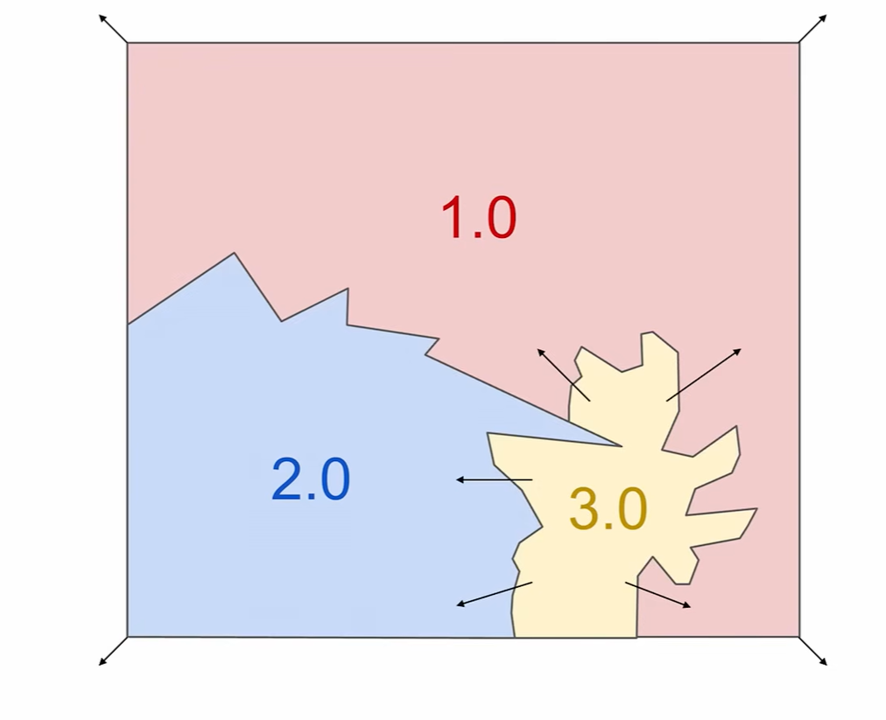
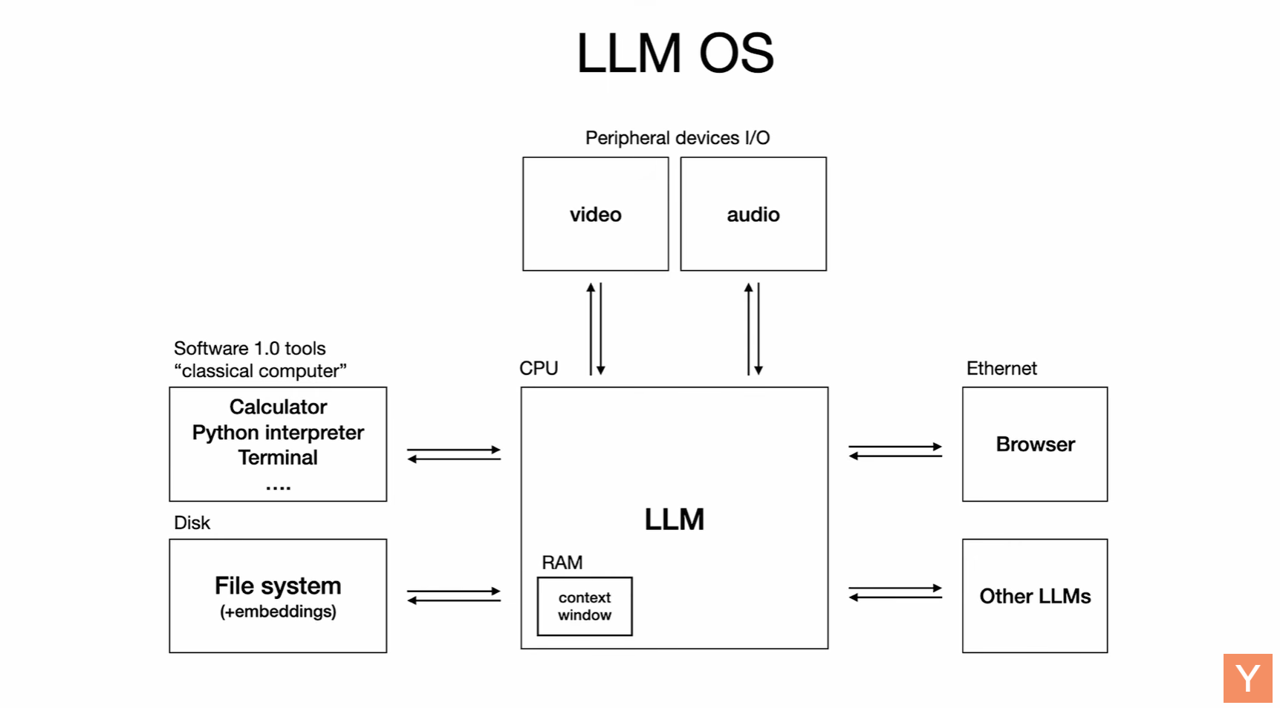
- Operating Systems: This is perhaps Karpathy’s strongest analogy. LLMs are increasingly complex software ecosystems, not simple commodities. They exhibit similar dynamics to operating systems with closed-source providers (like Windows/macOS) and open-source alternatives (like Linux, with the LLaMA ecosystem being a potential equivalent). Karpathy views the LLM as a “new kind of computer,” with context windows acting as memory, orchestrating computation for problem-solving. We are currently in a “1960s-ish era” where LLM compute is expensive and centralized in the cloud, forcing a “time-sharing” model, much like early computers.
The Psychology of LLMs
Karpathy describes LLMs as “stochastic simulations of people”. Trained on human text, they develop an “emergent psychology that is humanlike”. They possess:
- Encyclopedic Knowledge and Memory: LLMs can recall vast amounts of information, far more than any single human, due to the sheer volume of text they’ve processed. Karpathy compares this to the savant in the movie Rain Man.
- Cognitive Deficits: Despite their strengths, LLMs hallucinate, make up information, and lack a strong internal model of self-knowledge. They exhibit “jagged intelligence,” performing superhumanly in some areas while making basic human errors in others.
- Anterograde Amnesia: LLMs don’t natively learn and consolidate knowledge over time like humans do. Their context windows are like “working memory” that needs to be directly programmed, akin to the protagonists in Memento or 50 First Dates whose memories reset.
- Gullibility and Security Risks: LLMs are susceptible to prompt injection and may leak data, highlighting security concerns.
The challenge for developers is to program these “superhuman things that have a bunch of cognitive deficits” to leverage their power while working around their limitations.

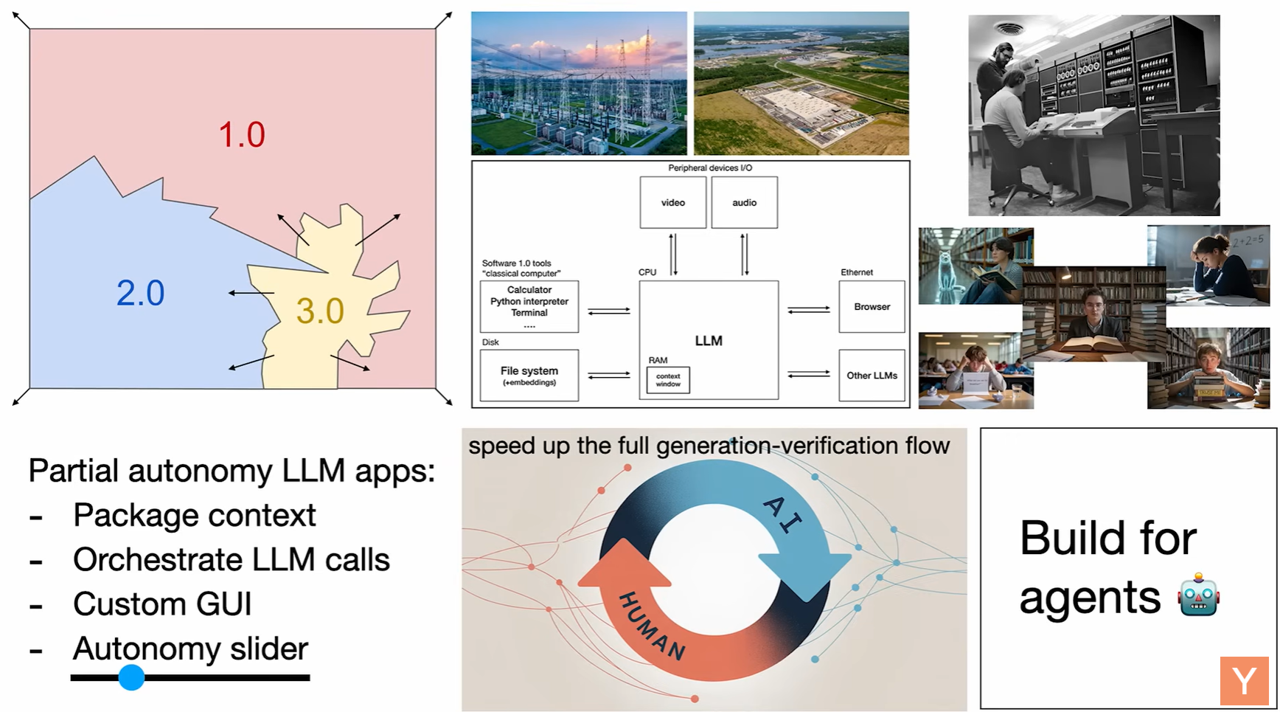
Opportunities: Partial Autonomy Apps and Agent-Oriented Design
Karpathy sees significant opportunities in partial autonomy apps. These applications integrate LLMs while maintaining a human in the loop for supervision. Key features of successful LLM apps include:
- Context Management: LLMs handle much of the underlying context.
- Orchestration of Multiple LLMs: Apps often coordinate various LLM calls (e.g., embedding models, chat models, diff models).
- Application-Specific GUI: A graphical user interface is crucial for auditing LLM work, allowing humans to quickly verify and accept/reject changes (e.g., red/green diffs). This speeds up the “generation-verification loop”.
- Autonomy Slider: Users can adjust the level of LLM autonomy based on the task’s complexity, from simple tap completion to full agentic control. This ensures humans stay “on the leash” and prevent the AI from generating overwhelming changes.
He emphasizes that while LLMs offer immediate productivity, we must be cautious about over-relying on fully autonomous agents. The development of self-driving cars, for instance, has taken much longer than initially anticipated, highlighting the complexity of real-world autonomy. The goal should be to build “Iron Man suits” (augmentations) rather than fully autonomous “Iron Man robots” at this stage.

Karpathy also highlights the unprecedented nature of “vibe coding,” where natural language, specifically English, acts as a programming language. This means “everyone is a programmer”. While this makes prototyping incredibly fast, the real challenge lies in making applications production-ready with authentication, payments, and deployment. This leads to his final point: the need to build for agents.
He advocates for creating digital infrastructure that agents can easily consume and manipulate. Examples include:
lm.txtfiles: A simple markdown file that tells LLMs what a domain is about, making it directly readable for them compared to parsing HTML.- LLM-friendly documentation: Transitioning documentation to formats like Markdown that LLMs can easily understand. Furthermore, replacing human-centric instructions like “click this” with equivalent curl commands allows agents to directly take actions.
- Tools for data ingestion: Services like “get ingest” and “deep wiki” that transform GitHub repositories or other complex data into LLM-friendly formats for analysis and prompting.
In conclusion, Karpathy stresses that we are in an “amazing time to get into the industry”. LLMs are akin to early operating systems, fallible yet powerful “people spirits” that require us to adapt our infrastructure. The future will involve a gradual shift on the “autonomy slider,” building increasingly capable partial autonomy products.